Guiding Instruction-based Image Editing via Multimodal Large Language Models
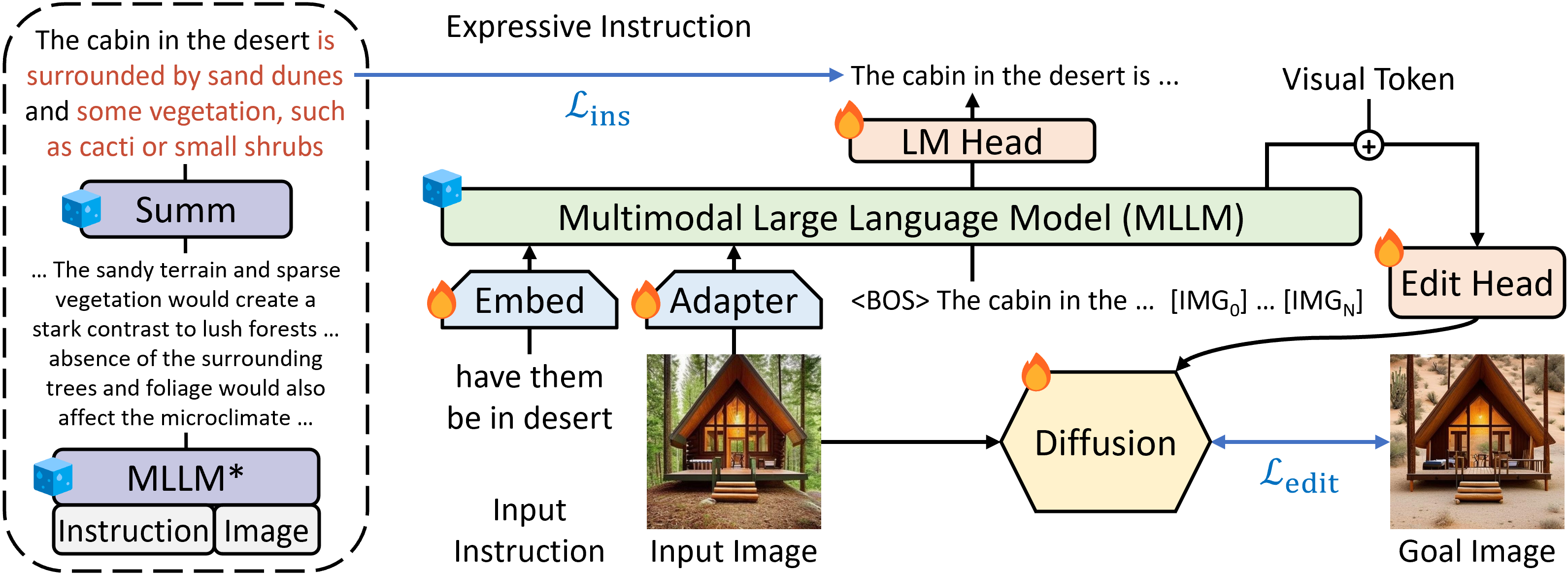
Instruction-based image editing improves the controllability and flexibility of image manipulation via natural commands without elaborate descriptions or regional masks. However, human instructions are sometimes too brief for current methods to capture and follow. Multimodal large language models (MLLMs) show promising capabilities in cross-modal understanding and visual-aware response generation via LMs. We investigate how MLLMs facilitate edit instructions and present MLLM-Guided Image Editing (MGIE). MGIE learns to derive expressive instructions and provides explicit guidance. The editing model jointly captures this visual imagination and performs manipulation through end-to-end training. We evaluate various aspects of Photoshop-style modification, global photo optimization, and local editing. Extensive experimental results demonstrate that expressive instructions are crucial to instruction-based image editing, and our MGIE can lead to a notable improvement in automatic metrics and human evaluation while maintaining competitive inference efficiency.
| Input | Instruction | InsPix2Pix | LGIE | MGIE | GroundTruth |
|---|---|---|---|---|---|
 |
turn the day into night |
 |
 |
 |
 |
 |
make the forest path into a beach |
 |
 |
 |
|
 |
make the frame red |
 |
 |
 |
|
 |
as if the shop was a library |
 |
 |
 |
|
 |
make it the vatican |
 |
 |
 |
|
 |
turn the sunset into a firestorm |
 |
 |
 |
|